SceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry
Lin Gao1,2
Jia-Mu Sun1,2
Kaichun Mo3
Yu-Kun Lai4
Leonidas J. Guibas3
Jie Yang1,2
1 Institute of Computing Technology, Chinese Academy of Sciences
2 University of Chinese Academy of Sciences
3 Stanford University
4 Cardiff University

Figure 1: Our deep generative model SCENEHGN encodes the indoor scene across multiple conceptual levels: the room, functional regions, furniture objects, and even fine-grained object part geometry. We utilize edges, including our proposed hyper-edges to strengthen the relations between objects during decoding. This enables some interesting applications, such as room editing with part-level geometry and scene interpolation. Our approach allows the entire 3D room to be represented and synthesized. Based on this, we can achieve part geometry editing (at different scales) in the scene, such as rigid transformation in a functional region and non-rigid deformation at the part level. Meanwhile, our network is capable of capturing the smooth latent space near similar scenes for plausible scene interpolation.
Abstract
3D indoor scenes are widely used in computer graphics, with applications ranging from interior design to gaming to virtual and augmented reality. They also contain rich information, including room layout, as well as furniture type, geometry, and placement. High-quality 3D indoor scenes are highly demanded while it requires expertise and is time-consuming to design high-quality 3D indoor scenes manually. Existing research only addresses partial problems: some works learn to generate room layout, and other works focus on generating detailed structure and geometry of individual furniture objects. However, these partial steps are related and should be addressed together for optimal synthesis. We propose SCENEHGN, a hierarchical graph network for 3D indoor scenes that takes into account the full hierarchy from the room level to the object level, then finally to the object part level. Therefore for the first time, our method is able to directly generate plausible 3D room content, including furniture objects with fine-grained geometry, and their layout. To address the challenge, we introduce functional regions as intermediate proxies between the room and object levels to make learning more manageable. To ensure plausibility, our graph-based representation incorporates both vertical edges connecting child nodes with parent nodes from different levels, and horizontal edges encoding relationships between nodes at the same level. Our generation network is a conditional recursive neural network (RvNN) based variational autoencoder (VAE) that learns to generate detailed content with fine-grained geometry for a room, given the room boundary as the condition. Extensive experiments demonstrate that our method produces superior generation results, even when comparing results of partial steps with alternative methods that can only achieve these. We also demonstrate that our method is effective for various applications such as part-level room editing, room interpolation, and room generation by arbitrary room boundaries.

Paper
SCENEHGN: Hierarchical Graph Networks for
3D Indoor Scene Generation with Fine-Grained Geometry
Code (Github)
Methodology
Hierarchical Scene Representation
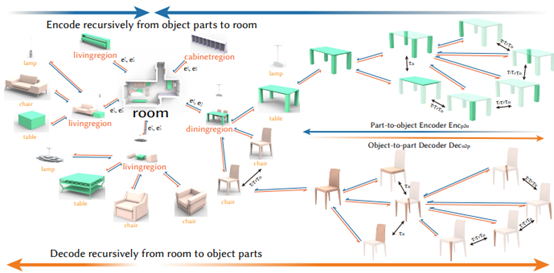
Figure 2: Hierarchical Scene Representation.Our scene hierarchy has four conceptual levels: the room root node, functional regions, objects, and object parts. To train the recursive autoencoder, we use an encoder network to summarize the features in a bottom-up fashion and a decoder network that reconstructs the scene hierarchy from the room root node to regions to objects and finally to object parts in a top-down manner. We also model the rich edge relationships at different levels in this process to enforce the validity of the generated scene structures.
Functional Region
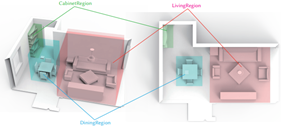
Figure 3. Functional Region Visualization. In the figure, a whole scene is divided into three functional regions including a Cabinet Region, a Dining Region, and a Living Region, which are highlighted in different colors. The separation is conducted by a spatial clustering algorithm DBSCAN, which is a density-based and non-parametric clustering algorithm, where the number of clusters is self-adaptive. We can see that an indoor scene can be divided reasonably
Binary Edges and Hyper Edges
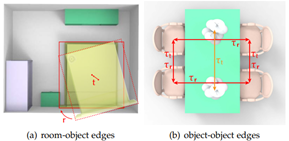

Figure 4. Binary Edges and Hyper Edges. We illustrate the two types of binary edges at the object level of our hierarchy. In (a), we show a binary edge example of the first kind which is defined between the room wall and an object. It encourages the object to locate within the boundary of the room and align with the room boundary. In (b), another type of binary edge describes the spatial relationship between two objects. For example, any pair of the four chairs have rich symmetry relationships of different kinds. We define two types of hyper-edges that exist across multiple objects: rotation and parallel. A rotation hyper-edge indicates that objects are rotated around a center, and a parallel hyper-edge indicates objects are placed collinearly.
Scene Generation
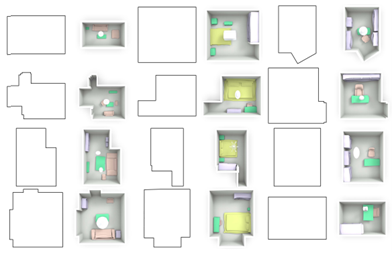
Figure 5. Scene Generation: Given the room boundary, we can utilize our trained decoder to generate new rooms. Our network is able to take arbitrary room boundariesas input to generate object layouts and geometric details in a recursive manner. The figure shows 12 generated rooms (4 living rooms, 4 bedrooms, and 4 libraries). From the results, our network learns the continuous latent space successfully, which can capture the plausible part geometries and reasonable object layout that fits the room boundary simultaneously.
Scene Interpolation

Figure 6. Scene Interpolation: We simultaneously interpolate on boundary and scene layout and feed them into the VAE decoder. Every interpolation step is a valid 3D scene layout, with the boundary deforming continuously and the layout changing according to the boundary. Note that the interpolation is only reasonable when the source and target are similar.
Room Generation from 3D Box Layout.
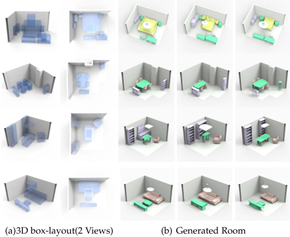
Figure 7. 3D scene generation from 3D box layout: We input a hierarchy consisting of 3D boxes into our RvNN-VAE with geometry information sampled from random distribution, then we encode the hierarchy, sample a latent vector and decode it into a complete 3D scene. We can see the positions of objects in the generated results are similar to the box layout, and the detailed geometry of the scenes looks harmonious.
Scene Editing.

Figure 8. Room Editing: The first column shows the original scene, followed by pairs of columns demonstrating the edits and their results. There are four edits to each of the two scenes. The first and second edits only alter the locations and orientations of the objects, the third edit deforms object parts, and fourth edit replaces the geometry of objects. From the results, we can observe that every object related to the edited object moves or deforms according to the edit.
Additional Materials
Video
|
|
BibTex
author={Gao, Lin and Sun, Jia-Mu and Mo, Kaichun and Lai, Yu-Kun and Guibas, Leonidas J. and Yang, Jie},
title={SceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023},
pages={1-18},
doi={10.1109/TPAMI.2023.3237577}
}
|
Last updated on Jan, 2023. |