TM-NET: Deep Generative Networks for Textured Meshes
Lin Gao1 Tong Wu1 Yu-Jie Yuan1 Ming-Xian Lin1
Yu-Kun Lai2 Hao(Richard) Zhang3
1Institute of Computing Technology, Chinese Academy of Sciences
2Cardiff University 3Simon Fraser University
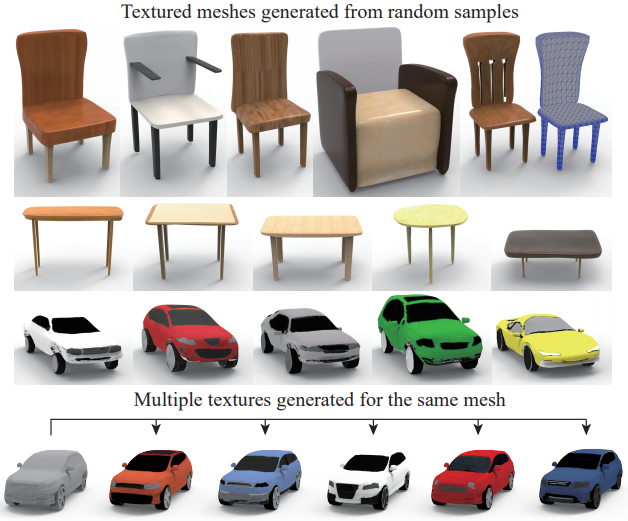
Figure: Our deep generative network, TM-NET, can generate textured meshes from random samples in a latent space (top) and synthesize multiple textures for the same input shape (bottom). Our texture generation is part-aware, where different shape parts may be textured differently. Furthermore, even if the underlying mesh is relatively low-resolution (e.g., the top right chair has < 4K vertices), the generated textures can exhibit the appearance of topological details (e.g., holes between the slats on the chair back).
Abstract
We introduce TM-NET, a novel deep generative model for synthesizing textured meshes in a part-aware manner. Once trained, the network can generate novel textured meshes from scratch or predict textures for a given 3D mesh, without image guidance. Plausible and diverse textures can be generated for the same mesh part, while texture compatibility between parts in the same shape is achieved via conditional generation. Specifically, our method produces texture maps for individual shape parts, each as a deformable box, leading to a natural UV map with minimal distortion. The network separately embeds part geometry (via a PartVAE) and part texture (via a TextureVAE) into their respective latent spaces, so as to facilitate learning texture probability distributions conditioned on geometry. We introduce a conditional autoregressive model for texture generation, which can be conditioned on both part geometry and textures already generated for other parts to achieve texture compatibility. To produce high-frequency texture details, our TextureVAE operates in a high-dimensional latent space via dictionary-based vector quantization. We also exploit transparencies in the texture as an effective means to model complex shape structures including topological details. Extensive experiments demonstrate the plausibility, quality, and diversity of the textures and geometries generated by our network, while avoiding inconsistency issues that are common to novel view synthesis methods.

Paper
TM-NET: Deep Generative Networks for Textured Meshes
Code
Data
[Link for ShapeNet Segmentation Data]
Methodology
Overview of TM-NET
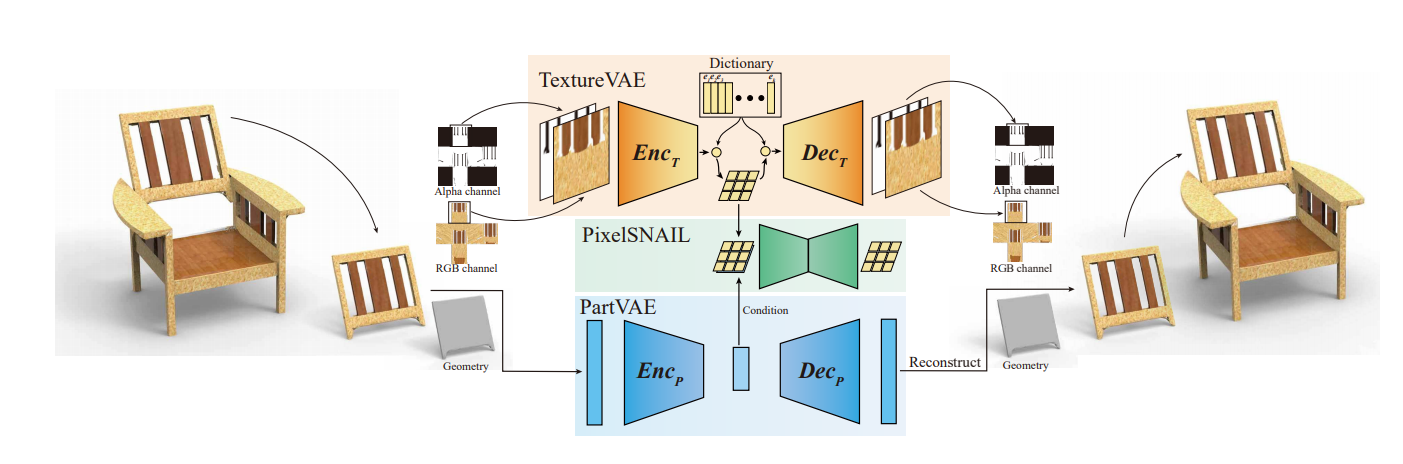
Figure:An overview of the key components of TM-NET, for textured mesh generation. Each part is encoded using two Variational Autoencoders (VAEs): PartVAE for geometry with EncP as the encoder and DecP as the decoder, and TextureVAE for texture with EncP as the encoder and DecP as the decoder. For texture generation, TM-NET designs a conditional autoregressive generative model, which takes the latent vector of PartVAE as condition input and outputs discrete feature maps. These feature maps are decoded as texture images for the input mesh geometry.
TextureVAE and PartVAE for Encoding a Textured Part
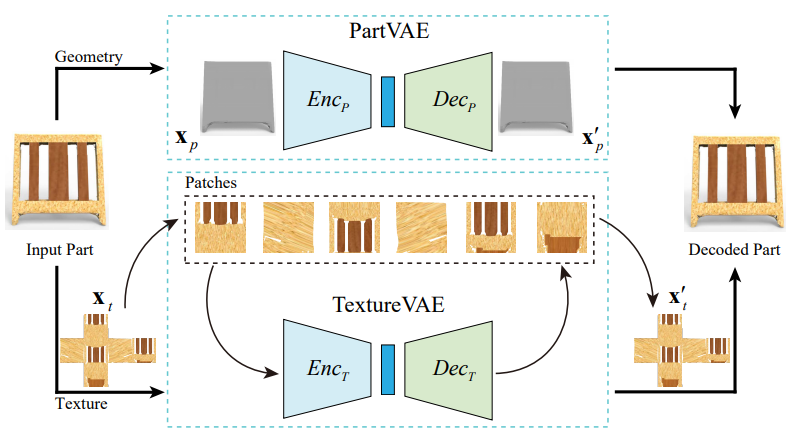
Figure: Network architecture for representing a textured part: a PartVAE for encoding part geometry and a TextureVAE for texture.
TextureVAE for Texture Encoding
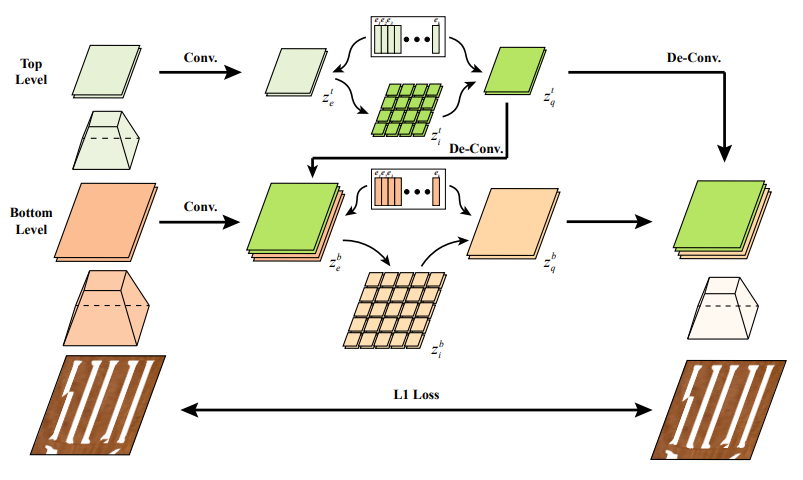
Figure: Network architecture of TextureVAE. The encoder maps the input image patch onto two continuous feature maps, top (t) and bottom (b). Then the dictionary-based vector quantization is performed. The decoder takes the discrete feature maps as input and reconstructs the image.
PixelSNAIL for Conditional Texture Generation
![]()
Figure: The architecture of our autoregressive generative model. The network takes an index matrix as input and geometry latent vector as condition and outputs reconstructed index matrix.
Shape Interpolation

Figure: Randomly sampled results of latent-space linear interpolation between chairs (first and last columns), comparing TM-NET to VON [Zhu et al. 2018], TF [Oechsle et al. 2019], and part-by-part alpha blending.
Geometry Guided Texture Generation

Figure: Randomly selected shape-conditioned texturing results by four samplings of the learned probability distribution conditioned only on input geometry (left). The seed parts are chair seats and tabletops, respectively. Note the plausible and diverse textures generated by TM-NET, as well as different textures generated for different parts in the same shape.
Textured Mesh Generation

Figure: Representative results of generated shapes with textures. We first randomly sample on the latent space of SP-VAE to generate structured meshes. We then use geometry latent as condition for PixelSNAIL to generate desired textures.
BibTex
author = {Lin Gao and Tong Wu and Yu-Jie Yuan and Ming-Xian Lin and Yu-Kun Lai and Hao Zhang},
title = {TM-NET: Deep Generative Networks for Textured Meshes},
journal = {ACM Transactions on Graphics (TOG)},
volume = {40},
number = {6},
pages = {263:1--263:15},
year = {2021}
}
|
Last updated on Aug, 2021. |