STAR-TM: STructure Aware Reconstruction of Textured Mesh from Single Image
Tong Wu1 Lin Gao1 Ling Xiao Zhang1
Yu-Kun Lai2 Hao(Richard) Zhang3
1Institute of Computing Technology, Chinese Academy of Sciences
2Cardiff University 3Simon Fraser University

Figure: Single-view reconstruction of textured meshes by our structure-aware method, STAR-TM. Top: three input images, with the third one taken “in the wild”. Bottom: reconstructed meshes in two views, with insets revealing the parts retrieved and assembled into the outputs. Note that the car wheels do not appear in the input image, but are well “hallucinated” by our learned transformer model for texture completion.
Abstract
We present a novel method for single-view 3D reconstruction of textured meshes, with a focus to address the primary challenge surrounding texture inference and transfer. Our key observation is that learning textured reconstruction in a structure-aware and globally consistent manner is effective in handling the severe ill-posedness of the texturing problem and significant variations in object pose and texture details. Specifically, we perform structured mesh reconstruction, via a retrieval-and-assembly approach, to produce a set of genus-zero parts parameterized by deformable boxes and endowed with semantic information. For texturing, we first transfer visible colors from the input image onto the unified UV texture space of the deformable boxes. Then we combine a learned transformer model for per-part texture completion with a global consistency loss to optimize inter-part texture consistency. Our texture completion model operates in a VQ-VAE embedding space and is trained end-to-end, with the transformer training enhanced with retrieved texture instances to improve texture completion performance amid significant occlusion. Extensive experiments demonstrate higher-quality textured mesh reconstruction obtained by our method over state-of-the-art alternatives, both quantitatively and qualitatively, as reflected by a better recovery of texture coherence and details.

Paper
TM-NET: Deep Generative Networks for Textured Meshes
Code
Methodology
Overview of STAR-TM

Figure: Overall pipeline of our method. Given a single image I as input, it predicts an initial mesh Minit, then retrieves a set of shape parts with a fixed UV parameterization to assemble a structured mesh MA. An intrinsic image decomposition network removes lighting effects from the input image I. Texture is then transferred from the input image to the visible regions of MA, at the proper pose. A texture completion network, based on a transformer, is trained to finally complete missing textures to obtain a fully textured mesh. Note that the table base in the green frame is composed of several deformed boxes.
Structure-Aware Texture Completion Transformer
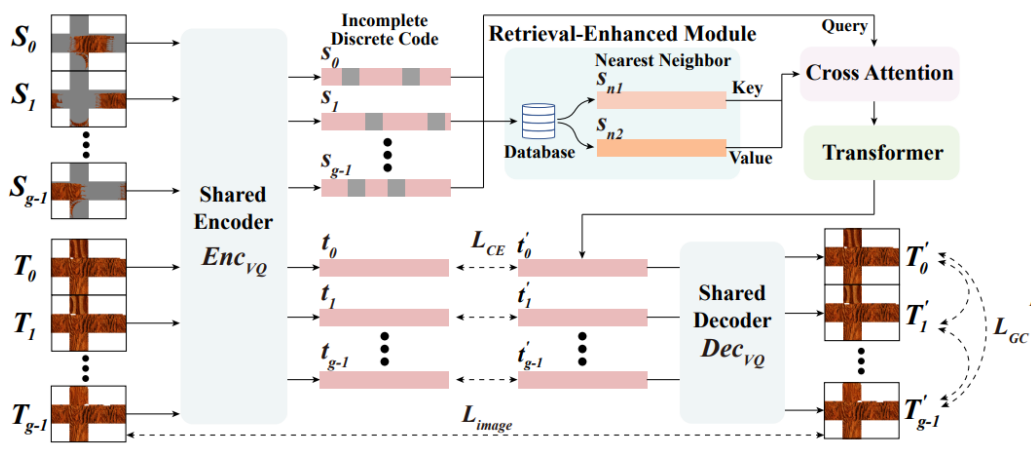
Figure: The architecture of our texture completion network. Our texture completion network takes several incomplete textures S0 , . . . , Sg−1 in the same semantic group as input and encodes them into discrete codes s0 , . . . , sg−1 . Our retrieval-enhanced module searches for the two nearest neighbors sn1 , sn2 for these discrete codes from the training set, which goes through a cross-attention module and a transformer decoder together with the discrete codes to predict the discrete codes of complete textures t′0, . . . ,t′g−1. At last the pre-trained vector quantization decoder decodes the predicted discrete codes into complete textures T′0, . . . , T′g−1 for these parts. Our model minimizes the difference between predicted complete textures and ground truth and the perceptual differences between predicted complete images of different parts via a global consistency loss.
Textured Mesh Reconstruction on ShapeNet Dataset
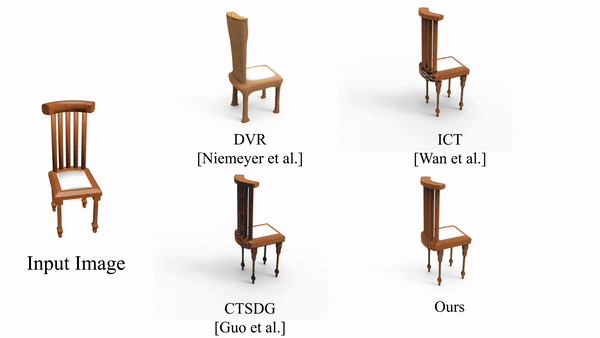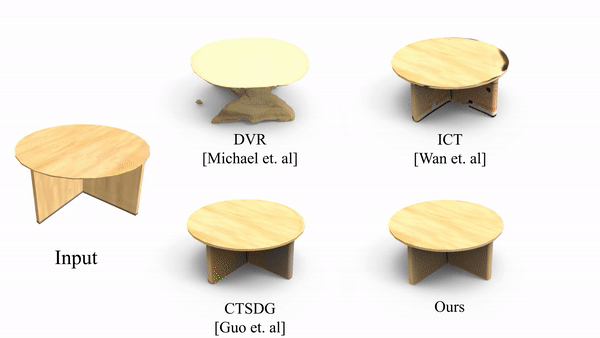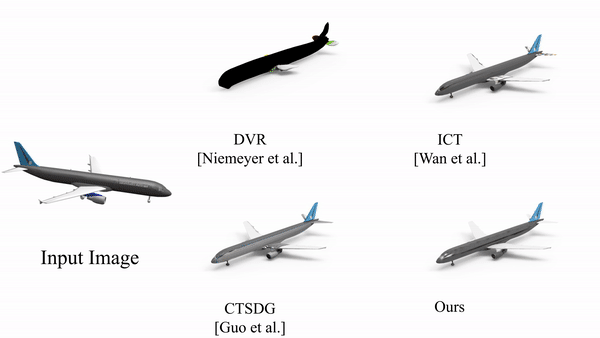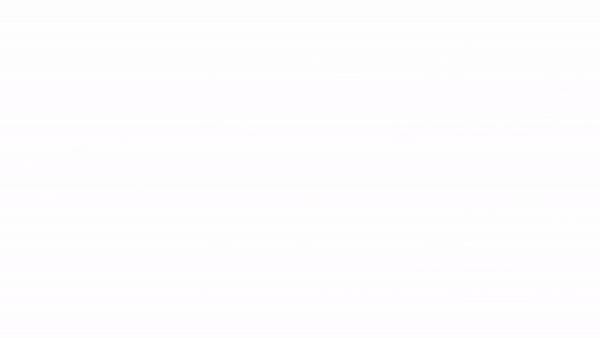
Figure:Qualitative comparison between textured shape reconstruction by DVR, CTSDG, ICT, and our method STAR-TM. We show reconstructed textured meshes from a novel viewpoint, for examples from all four object categories.
Textured Mesh Reconstruction on Real Images

Figure:Textured mesh reconstruction from images in the wild by our method. The input image is shown on the left in each pair.
BibTex
author = {Wu, Tong and Gao, Lin and Zhang, Ling-Xiao and Lai, Yu-Kun and Zhang, Hao},
title = {STAR-TM: STructure Aware Reconstruction of Textured Mesh From Single Image},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
volume = {},
number = {},
pages = {1-14},
year = {2021}
}
|
Last updated on Aug, 2021. |