DeepFaceVideoEditing: Sketch-based Deep Editing of Face Videos
Feng-Lin Liu1,2 Shu-Yu Chen1 Yu-Kun Lai3 Chunpeng Li1 Yue-Ren Jiang1,2 Hongbo Fu4 Lin Gao1,2 *
1 Institute of Computing Technology, Chinese Academy of Sciences
2 University of Chinese Academy of Sciences
3 Cardiff University
4 City University of Hong Kong
* Corresponding author
Accepted by Siggraph 2022(ACM Transactions on Graphics)
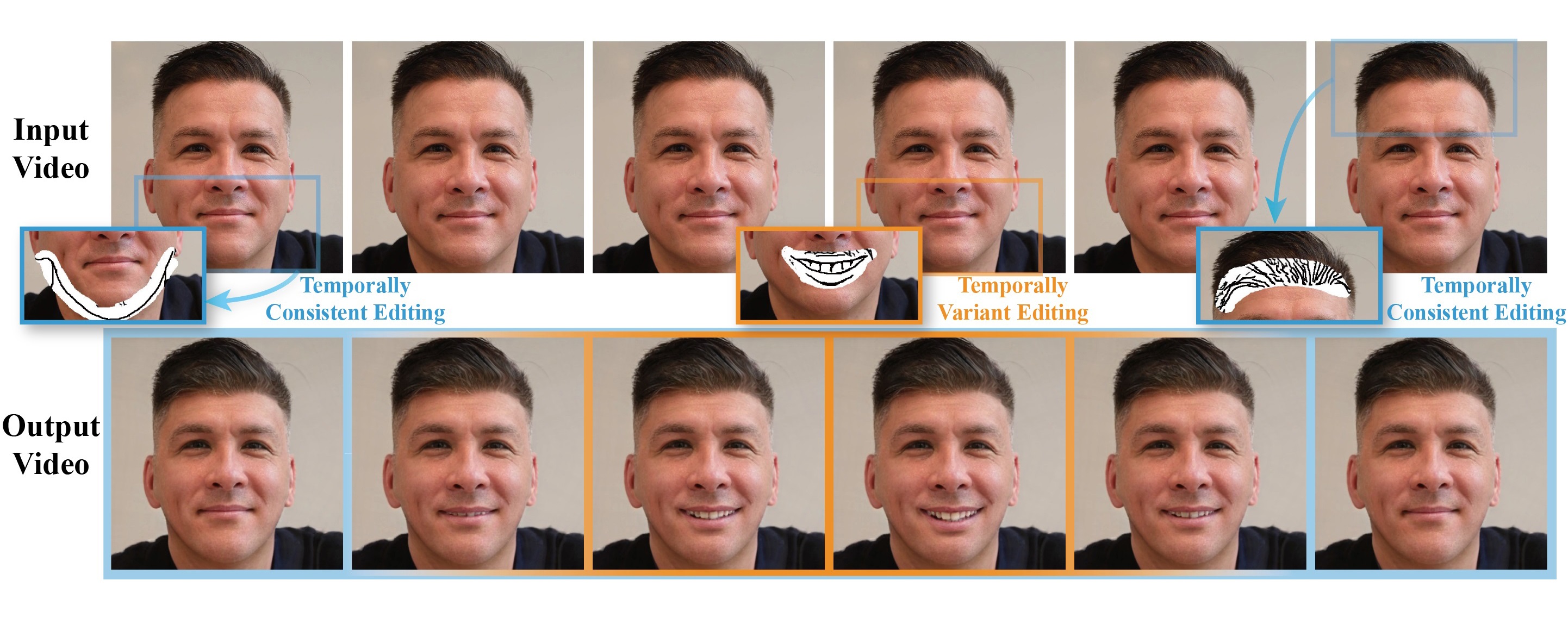
Figure: Our method, named DeepFaceVideoEditing, allows users to intuitively edit face video by sketches and masks. Given an input face video, users can select multiple frames and draw sketches within selected mask regions to apply diverse editing operations. Our system supports two types of manipulations, namely, Temporally Consistent Editing, which has significant influence on the entire video (blue boxes), and Temporally Variant Editing, which dynamically changes in the timeline (orange boxes). The editing effects of these two types are propagated to all the video frames in different manners. The output video fuses all input sketch editing effects and shows stable temporal consistency. Please refer to the accompanying video for various editing results with our technique. Original videos courtesy of Vanessa Garcia.
Abstract
Sketches, which are simple and concise, have been used in recent deep image synthesis methods to allow intuitive generation and editing of facial images. However, it is nontrivial to extend such methods to video editing due to various challenges, ranging from appropriate manipulation propagation and fusion of multiple editing operations to ensure temporal coherence and visual quality. To address these issues, we propose a novel sketch-based facial video editing framework, in which we represent editing manipulations in latent space and propose specific propagation and fusion modules to generate high-quality video editing results based on StyleGAN3. Specifically, we first design an optimization approach to represent sketch editing manipulations by editing vectors, which are propagated to the whole video sequence using a proper strategy to cope with different editing needs. Specifically, input editing operations are classified into two categories: temporally consistent editing and temporally variant editing. The former (e.g., change of face shape) is applied to the whole video sequence directly, while the latter (e.g., change of facial expression or dynamics) is propagated with the guidance of expression or only affects adjacent frames in a given time window. Since users often perform different editing operations in multiple frames, we further present a region-aware fusion approach to fuse diverse editing effects. Our method supports video editing on facial structure and expression movement by sketch, which cannot be achieved by previous works. Both qualitative and quantitative evaluations show the superior editing ability of our system to existing and alternative solutions.
Code
BibTex
author = {Liu, Feng-Lin and Chen, Shu-Yu and Lai, Yu-Kun and Li, Chunpeng and Jiang, Yue-Ren and Fu, Hongbo and Gao, Lin},
title = {{DeepFaceVideoEditing}: Sketch-based Deep Editing of Face Videos},
journal = {ACM Transactions on Graphics},
year = {2022},
volume = 41,
pages = {167:1--167:16},
number = 4
}